
昨天下午大概五點多,突然Claude 大當機。社群上許多工程師因此崩潰~高喊下班惹
心想「疑~不是大當機?網頁還可以看得到狀況?」
原來是使用 Statuspage ( https://www.atlassian.com/software/statuspage) 服務。
大型網站架構..net 架構師.rabbitMQ.redis.行動開發.APP開發教學.PHP Laravel開發..net core C# 開發.架構師之路.Delphi開發.資料庫程式.進銷存.餐飲POS系統
昨天下午大概五點多,突然Claude 大當機。社群上許多工程師因此崩潰~高喊下班惹
心想「疑~不是大當機?網頁還可以看得到狀況?」
原來是使用 Statuspage ( https://www.atlassian.com/software/statuspage) 服務。

OpenAI 的devday推出 Agent Builder後,make也推出make code,讓Agent Builder產出的code貼入後,與現有的make 流程結合
九月底Chrome for Developers 發佈AI 代理程式適用的 Chrome 開發人員工具(MCP)
加上
{
"mcpServers": {
"chrome-devtools": {
"command": "npx",
"args": ["chrome-devtools-mcp@latest"]
}
}
}
如果使用VSCODE的話
開啟vs code ,按下 【Ctrl+Shift+P】 快捷鍵,選擇MCP:開啟使用者設定,然後
{ "servers": { • "chrome-devtools": { "command": "npx", "args": ["chrome-devtools-mcp@latest"] } } }
就可以讓AI呼叫網頁了。
可以用markdown語法將測試案例寫至md檔,透過ai執行。

https://github.com/ChromeDevTools/chrome-devtools-mcp
以前最不愛考認證的我,因為在研發單位當主管秉持身先士卒的理念。從ipas ai 規劃師初級自己去考取外,剛好看到google推出免費的Google Gemini Certified Educator 認證教師證書,花了半小時裸考通過。主要為考google gemini 與NotebookLM以及一些相關ai的功能,對現在每天與ai為伍的我算是得心應手,證書有效期限為3年。。
註冊考式網址 https://educertifications.google/


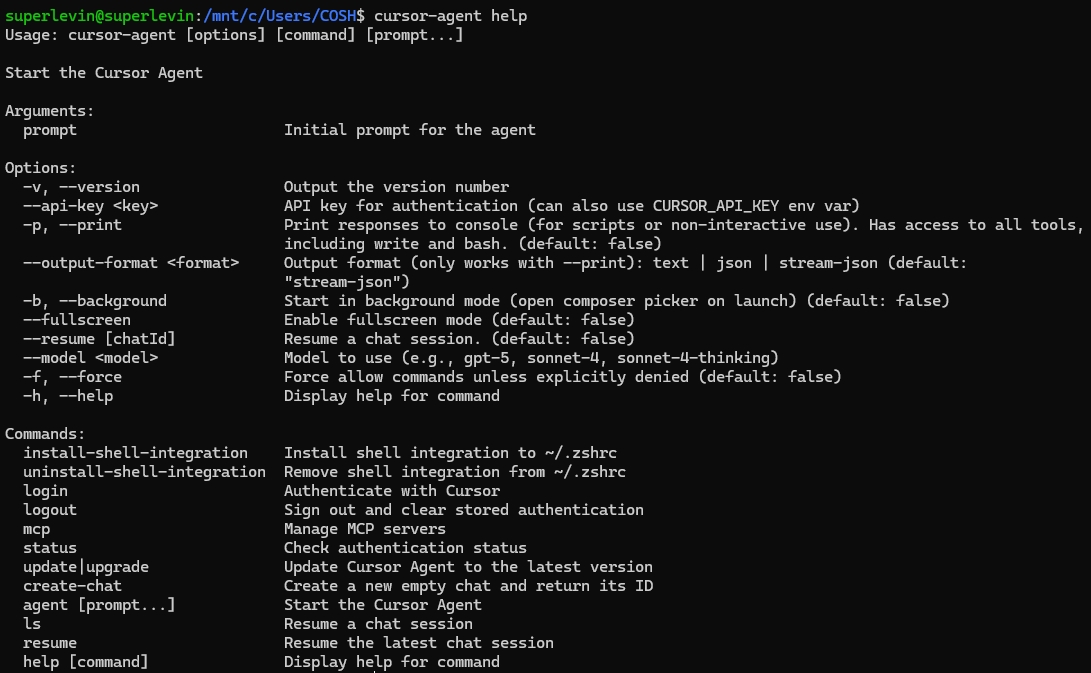
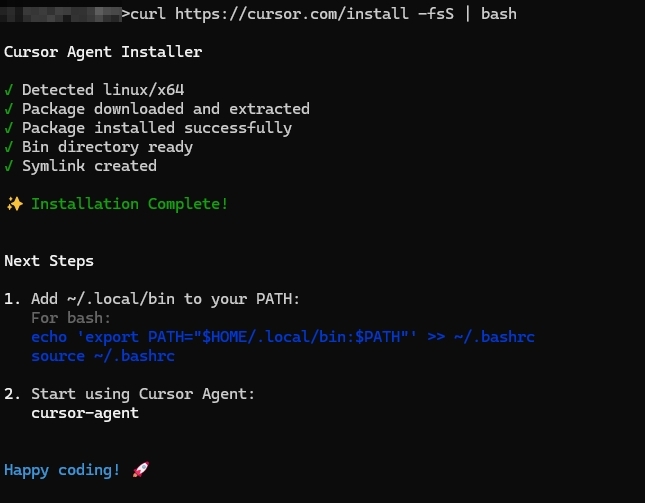
今天收到cursor發來的信,推出cursor cli。安裝方法 curl https://cursor.com/install -fsS | bash
安裝後輸入 cursor-agent 執行
官方網址: https://cursor.com/cn/cli
不過目前看來是在wsl環境下,但可以讓cursor agent 跑在像jetbrians這類ide也是不錯。可以讓cursor的威力發揮在更多地方了
原來習慣使用meta llama 模型,後來OpenAI直接釋出Open Source的 gpt-oss-20B, 就開始改用它當落地模型。
curl --location 'http://xxxx:11434/api/chat' \
--header 'Content-Type: application/json' \
--header 'Accept: application/json' \
--data '{
"model": "gpt-oss:20b",
"messages": [
{"role": "system", "content": "你是一位專業助理,請用繁體中文回覆。"},
{"role": "user", "content": "用三點說明向量資料庫是什麼?"}
],
"stream": false,
"options": {
"temperature": 0.7,
"num_ctx": 8192
},
"keep_alive": "30m"
}'
curl --location 'https://openrouter.ai/api/v1/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer sk-or-v1-xxxxxx' \
--data '
{
"model": "openai/gpt-oss-20b:free",
"messages": [
{"role": "system", "content": "你是一位專業助理,請用繁體中文回覆。"},
{"role": "user", "content": "用三點說明向量資料庫是什麼?"}
],
"stream": false,
"options": {
"temperature": 0.7,
"num_ctx": 8192
},
"keep_alive": "30m"
結合終端機中的 Claude Code 與可視化桌面應用 Claudia,可同時享有強大 AI 編程能力與友善 GUI 體驗,大幅提升開發效率與可視化管理。
Claude Code
由 Anthropic 開發的「Agentic 編程工具」,直接嵌入您熟悉的終端機,能透過自然語言指令理解並操作整個程式碼庫,執行測試、修復錯誤、搜尋 git 歷史等任務。
Claudia
開源桌面應用(基於 Tauri),為 Claude Code 增添直觀的圖形化介面,整合專案管理、即時使用量儀表板、MCP 伺服器管理與沙盒環境,免去頻繁輸入 CLI 指令的困擾。
| 優勢面向 | Claude Code (CLI) | Claudia (GUI) |
|---|---|---|
| 學習曲線 | 低,熟悉 CLI 後快速上手 | 更低,點擊式操作不需記憶指令 |
| 上下文理解 | 直接載入整個專案結構,依賴 CLAUDE.md 最佳化 |
同樣支援 CLAUDE.md,並可視化呈現關鍵內容 |
| 任務自動化 | 鏈結多步驟指令,適合 CI/CD 自動化 | 一鍵執行常用流程,並提供「檢查點」還原功能 |
| 專案管理 | 需手動切換分支、查詢日誌 | Projects 面板一覽所有 Session,點擊即可回顧 |
| 使用量與成本追蹤 | 無內建可視化 | 即時顯示 API 使用量、Token 成本與統計分析 |
| 安全沙盒 | 需手動設定權限 | 內建 seccomp/Seatbelt 沙盒,細粒度權限控管 |
安裝 Node.js (v18+),並確認 npm 可用
安裝 Claude Code
npm install -g @anthropic-ai/claude-code
驗證:執行 claude --version 應顯示版本號。
下載並安裝 Claudia
方式一:從 GitHub Releases 取得最新的 macOS/Windows/Linux 執行檔
方式二(進階用法):
git clone https://github.com/getAsterisk/claudia.git
cd claudia
yarn install
yarn tauri build
執行後即會開啟可視化介面。
互動式開發
CLI:claude 開啟 REPL,輸入「請幫我新增一個 POST /users API」
GUI:在 Claudia 中點擊「New Session」,選擇系統提示,再輸入需求
除錯與測試
CLI:claude run test 自動執行測試並修復失敗測試
GUI:在「Timeline」檢視每次測試結果差異,快速回溯錯誤
版本控制
CLI:claude git merge 自動解決衝突
GUI:在「Projects」面板切換分支並視覺化比較差異
自訂 AI 智能體
建立 CLAUDE.md 記錄專案慣例與常用指令
GUI 中匯入/編輯 CLAUDE.md,讓 Claude 記憶專案規範
環境優化
在專案根目錄放置 CLAUDE.md,記錄測試命令、程式風格與常用工具,讓 Claude 建立持久記憶。
CI/CD 自動化
結合 Claude Code CLI 於 GitHub Actions,於 PR 自動執行程式碼檢查與合併衝突解決。
多語言支援
透過 Claudia MCP 管理器,註冊多個 Model Context Protocol 伺服器,讓 Claude 跨平台、跨服務庫檢索文件。
團隊協作
使用 Claudia 的「檢查點」功能截取多個開發階段,並匯出差異報告,供團隊成員 review。
將 Claude Code 與 Claudia 結合,既保有終端機指令的靈活與自動化能力,又能享有 GUI 的可視化便捷,適合各種規模與需求的專案。無論是程式新手,或是追求效率的資深開發者,都能透過這套組合顯著提升開發體驗與產出品質。
原本在vscode就裝有github copilot 這個AI 程式寫作的輔助工具,但因為最近終端式的代理從codex cli 到claude code以及最新的gemini cli都太強了!於是想說多二個代理人也不錯~


![]() 先記錄一下如何安裝,從最簡單的Gemini Cli (https://github.com/google-gemini/gemini-cli)好了,官方部落格文章在此「Gemini CLI:你的開源 AI 代理」
先記錄一下如何安裝,從最簡單的Gemini Cli (https://github.com/google-gemini/gemini-cli)好了,官方部落格文章在此「Gemini CLI:你的開源 AI 代理」
首先,要先安裝 node.js 版本要20或更高 (下載安裝 https://nodejs.org/en/download ),安裝完成後直接在命令提示字元下輸入
npm install -g @google/gemini-cli
接著輸入
gemini
然後會出現設定與驗證後就可以使用了!
Gemini code完整命令說明
Gemini code說明手冊
接下來要處理比較麻煩的claude code。
目前claude在windows只支援WSL(Windows Subsystem for Linux)模式安裝,所以必需先看一下WSL到底是什麼以及如何使用 WSL 在 Windows 上安裝 Linux ,接著輸入
wsl --install wsl --set-default-version 2 # 確保使用 WSL2 wsl --set-default Ubuntu # 如果有多個版
接著進入wsl
sudo apt update #更新 sudo apt upgrade #升級 sudo apt install nodejs npm #安裝nodejs 跟npm npm install -g @anthropic-ai/claude-code #安裝claude code
安裝完成即可。
https://github.com/getAsterisk/claudia
安裝openai codex
npm i -g @openai/codex

能夠與中臺科技大學結緣,主是因為國泰電腦的李信宏總經理的關係,因為李總在DELPHI的造詣以及醫療系統、檢驗系統開發的成就,因為李總沒空的原因,再加上一直習慣透過部落格記錄問題解決方式,在十多年前就與李桂春老師、王國安老師持續合作,從還沒重新到公司就職,就以個人開發工作室的名義擔任產業學院的講師,因此有了五年左右的講師經驗~後來因為工作的關係,就逐漸減少上課的時間,專心在系統開發架構以及人工智慧相關技術的學習以及鑽研。
最近因為王國安老師接下系主任的原因,身為老朋友的關係,當然就是意氣相挺 🙂 也趁著特休假稍微放鬆一下,且持續與年輕人有一定的互動與瞭解,也讓自己在管理上可以有更多瞭解。於是今天又擔任了評審~ 🙂 這次有VR、NO-CODE、AI等元素,也是挺不錯的體驗。
